XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition (29 page)
Read XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition Online
Authors: Michael Kay

When you invoke an XSLT processor to apply a particular stylesheet to a particular source document, the first thing it does is to read and parse these documents and create internal tree representations of them in memory. Once this preparation is complete, the transformation process can start.
The first step in the transformation process is usually to find a template rule that matches the document node of the source tree. If there are several possible candidates, there is a conflict resolution policy to choose the best fit (see page 79 for details). If there is no template rule that matches the document node, a built-in template is used. The XSLT processor then evaluates the contents of this template rule.
XSLT 2.0 also allows you to start the transformation by supplying an initial node other than the document node. As discussed in the previous section, you can even start the transformation without supplying an initial node at all, by providing the name of the first template to be evaluated.
Contents of a Template Rule
The content of an
xml:space
attribute. This sequence of elements and text nodes is called a
sequence constructor
, because the result of evaluating it is itself a sequence.
Elements in the sequence constructor can be classified as either instructions or data, depending on their namespace. Text nodes are always classified as data. When the sequence constructor is evaluated, the instructions are evaluated, and the result of each instruction is added to the result sequence. The data nodes are copied to the result tree. Elements that are classified as data are officially termed
literal result elements
.
Consider the following template rule:
…
The end
The body of this template rule consists of two instructions (
element), and some text ( The end
The end , preceded and followed by significant whitespace). When this template is evaluated, the instructions are executed according to the rules for each individual instruction, and literal result elements and text nodes are copied (as element nodes and text nodes, respectively) to the result sequence.
, preceded and followed by significant whitespace). When this template is evaluated, the instructions are executed according to the rules for each individual instruction, and literal result elements and text nodes are copied (as element nodes and text nodes, respectively) to the result sequence.
It's simplest to think of this as a sequential process, where evaluating a sequence constructor causes evaluation of each of its components in the order they appear. Actually, because XSLT is largely side-effect-free, they could be executed in a different order, or in parallel. The important thing is that after evaluating this sequence constructor, the result sequence will contain a comment node (produced by the
element node (produced by the
literal result element), and the text nodeThe end. The order of these items in the result sequence corresponds to the order of the instructions in the stylesheet, although in principle the XSLT processor is free to execute the instructions in any order it likes.
If I hadn't included the...within the
element, this would be the end of the matter. But when a literal result element such as
is evaluated, its content is treated as a sequence constructor in its own right, and this is evaluated in the same way. It can again contain a mixture of instructions, literal result elements, and text. As we'll see in the next section, the result sequence produced by this sequence constructor is used to create the nodes that are attributes and children of the new
element.
Sequence Constructors
Sequence constructors play such an important role in the XSLT 2.0 processing model that it's worth studying them in some detail.
As we have seen, the content of an
template
, though few people used the term correctly. The new name
sequence constructor
reflects a change in the way the processing model is described, and a change in its capability: a sequence of instructions can now be used to produce any sequence of items, not necessarily a sequence of sibling nodes in a tree.
Many other XSLT elements are also defined to have a sequence constructor as their content. For example, the contents of an
- o - 0 - o -
- o - 0 - o -
Viewed as a tree, using the notation introduced earlier in this chapter, this has the structure shown in
Figure 2-9
. There are three sequence constructors, indicated by the shaded areas. Within the sequence constructors on this tree, there are four kinds of nodes: text nodes, XSLT instructions (such as
test=“position()=last()”
, not shown), and literal result elements (such as
), which are elements to be written to the result tree.
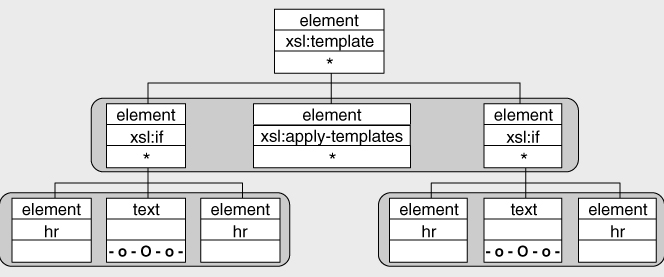
A sequence constructor is the nearest equivalent in XSLT to a block or compound statement in a block-structured programming language such as C or Java, and like blocks in C or Java, it defines the scope of any local variables declared within the block.
A sequence constructor is a sequence of sibling nodes in the stylesheet. Comment and processing instruction nodes are allowed, but the XSLT processor ignores them. The nodes of interest are text nodes and element nodes.