XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition (582 page)
Read XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition Online
Authors: Michael Kay

Using Keys for Grouping
Because keys provide an efficient way of retrieving all the nodes that share a common value, they are useful when you need to group nodes with common values in the output.
This technique is sometimes called the Muenchian grouping method, after Steve Muench of Oracle who introduced it. In XSLT 1.0, it was the only way of performing grouping efficiently. In XSLT 2.0, the
To solve any grouping problem, you need two nested loops. The outer loop selects one node to act as a representative of each group, typically the first node in document order that is a member of the group. The processing associated with this node outputs information about the group as a whole, typically the common value used to group the nodes together, perhaps with counts or subtotals calculated over the members of the group, plus any necessary formatting. The inner loop then processes each member of the group in turn.
With the Muenchian method, a key is defined on the common value that determines group membership. For example, if all the cities in a country compose one group, then the key definition will be as follows.
The outer loop selects one city for each country. The way of doing this is to select all the cities, and then filter out those that are not the first in their country. You can tell that a city is the first one for its country by comparing it with the first node in the sequence returned by the
key()
function for that country.
The is
is operator is new in XPath 2.0. In an XSLT 1.0 stylesheet, the equivalent expression would apply
operator is new in XPath 2.0. In an XSLT 1.0 stylesheet, the equivalent expression would apply
generate-id()
to both operands, and compare the results using the=operator.
Within this loop the code can output any heading it needs, such as the name of the country. It can then start an inner loop to process all the cities in this country, which it can find by using the key once again.
The following shows a complete example of this technique.
Example: Using Keys for Grouping
This example creates a list of cities, grouped by country.
Source
The source
cities.xml
is a list of cities.
Stylesheet
The stylesheet
citygroups.xsl
is as follows:
xmlns:xsl=“http://www.w3.org/1999/XSL/Transform”
version=“2.0”
>
Output
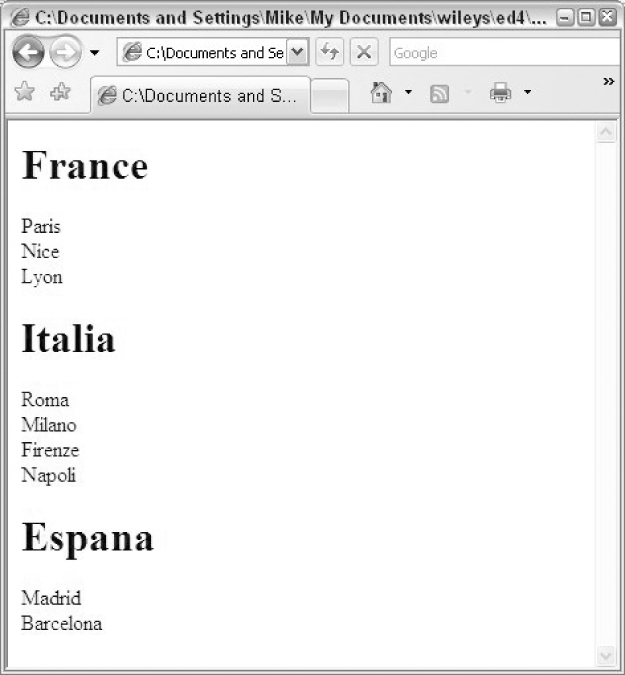
Viewed in a browser, the output is as shown in
Figure 13-2
.
See Also
id()
on page 802
lang
The
lang()
function tests whether the language of a given node, as defined by the
xml:lang
attribute, corresponds to the language supplied as an argument.
For example, if the context node is the elementlang(‘fr’)would return
true
.
Changes in 2.0
An optional second argument has been added to allow nodes other than the context node to be tested.
Signature
| Argument | Type | Meaning |
| language | xs:string | The language being tested |
| node (optional) | node() | The node being tested. If omitted, the context node is tested. |
| Result | xs:boolean | true if the language of the selected node is the same as, or a sublanguage of, the language being tested . |
Effect
The function tests the node identified by the second argument if present, or the context node if it is omitted. When the second argument is absent, a runtime error occurs if there is no context item, or if the context item is not a node.
The language of the selected node is determined by the value of its
xml:lang
attribute, or if it has no such attribute, by the value of the
xml:lang
attribute on its nearest ancestor node that does have such an attribute. If there is no
xml:lang
attribute on any of these nodes, the
lang()
function returns
false
.
The
xml:lang
attribute is one of the small number of attributes that are given a predefined meaning in the XML specification (in fact, you could argue that it is the only thing in the XML specification that has anything to say about what the contents of the document might mean to its readers). The value of the attribute is a language identifier as defined in RFC 3066; this takes one of the following four forms:
- A two- or three-letter language code defined in the international standard ISO 639. For example, English isenand French isfr. This can be given in either upper case or lower case, though lower case is usual.
- A language code as above, followed by one or more subcodes: each subcode is preceded by a hyphen-. For example, US English is “en-US”; Canadian French is “fr-CA”. The first subcode, if present, must be either a two-letter country code from the international standard ISO 3166 or a subcode for the language registered with IANA (Internet Assigned Numbers Authority). The ISO 3166 country codes are generally the same as Internet top-level domains; for example, “DE” for Germany or “CZ” for the Czech Republic, but with the notable exception of the United Kingdom, whose ISO 3166 code (for some reason) is “GB” rather than “UK”. These codes are generally written in upper case. The meaning of any subcodes after the first is generally not defined (though a few have been registered with IANA), but they must contain ASCII letters (a–z, A–Z) only.
- A language code registered with IANA (see
http://www.isi.edu/in-notes/iana/assignments/languages/
), prefixed “i-”, for example, “i-Navajo”. - A user-defined language code, prefixed “x-”, for example, “x-Java” if the element contains a Java program.