XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition (598 page)
Read XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition Online
Authors: Michael Kay

Example: Unicode Normalization
This example shows the effect of normalizing the string gar
gar
ç
on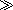 first to NFC, then to NFD, and then back to NFC. Note that 231 (xE7) is the Unicode codepoint for lower-case C with cedilla, while 807 (x0327) is the codepoint for a combining cedilla.
first to NFC, then to NFD, and then back to NFC. Note that 231 (xE7) is the Unicode codepoint for lower-case C with cedilla, while 807 (x0327) is the codepoint for a combining cedilla.
Stylesheet
Output
The value supplied for the
normalization-form
argument is converted to upper case, and leading and trailing spaces are removed.
Usage
The subject of character normalization has a long, tortured history. There have always been two interest groups concerned with character encoding: those primarily interested in data processing have favored fixed-length encodings of each character, with composite characters treated as a single unit, while those more concerned with publishing and printing have favored variable-length encodings in which the separate parts of a composite character (for example, a base letter and a diacritical mark) were encoded separately. Inevitably, the only way both communities could be satisfied was by a standard that allowed both, and that is exactly what Unicode does. The letter å
å for example (which is widely used in Swedish) can be encoded either using the single codepoint x00 C5 (called
for example (which is widely used in Swedish) can be encoded either using the single codepoint x00 C5 (called
LATIN CAPITAL A WITH RING ABOVE
) or by the two codepoints x0041 (
LATIN CAPITAL LETTER A
) followed by x030A (
COMBINING RING ABOVE
). To make matters even worse, there is also a separate code x212B (
ANGSTROM SIGN
), which is visually indistinguishable from the letteråbut has a separate code because it is considered to have its own meaning.
This means that unless special precautions are taken, when you search for text containing the characterå, you will not find it unless you choose the same representation as is used in the text you are searching. This applies not only to the textual content, but also to the markup: all three representations of this character are acceptable in XML names, and if you use one representation in the source XML, and a different representation in a path expression, then they won't match.
Unicode normalization is an algorithm that can be applied to Unicode strings to remove these arbitrary differences.
The W3 C Working Draft
Character Model for the World Wide Web 1.0: Normalization
(
http://www.w3.org/TR/charmod-norm/
), specifies that documents on the Web should be subject to “early normalization”: that is, they should be normalized at the time they are created, and it advocates the use of a particular normalization algorithm called NFC (further details below). If everyone followed this advice, there would be no need for a
normalize-unicode()
function in XPath. But unfortunately, there is little chance of this happening.
The normalization algorithms have been published in Unicode Technical Report #15 (
http://www.unicode.org/unicode/reports/tr15
). There are several, notably normalization forms C, D, KC, and KD, and “fully normalized”. (Why have one standard when you can have five?) The default used by the
normalize-unicode()
function is NFC (normalization form C), but the other forms can be requested using the second parameter to the function, provided that the implementation supports them—they aren't mandatory.
Normalization forms C and KC replace decomposed characters by composed characters; in our example usingå, they choose the single-codepoint representation x00 C5 in preference to the two-codepoint representation x0041x030A. Normalization forms D and KD prefer the decomposed representation, that is x0041x030A.