Authors: Mehmed Kantardzic
Data Mining (87 page)

This book gives a sound understanding of data-mining principles. The primary orientation of the book is for database practitioners and professionals with emphasis on OLAP and data warehousing. In-depth analysis of association rules and clustering algorithms is the additional strength of the book. All algorithms are presented in easily understood pseudo-code and they are suitable for use in real-world, large-scale data-mining projects including advanced applications such as Web mining and text mining.
11
WEB MINING AND TEXT MINING
Chapter Objectives
- Explain the specifics of Web mining.
- Introduce a classification of basic Web-mining subtasks.
- Illustrate the possibilities of Web mining using Hyperlink-Induced Topic Search (HITS), LOGSOM, and Path Traversal algorithms.
- Describe query-independent ranking of Web pages.
- Formalize a text-mining framework specifying the refining and distillation phases.
- Outline latent semantic indexing.
11.1 WEB MINING
In a distributed information environment, documents or objects are usually linked together to facilitate interactive access. Examples for such information-providing environments include the World Wide Web (WWW) and online services such as America Online, where users, when seeking information of interest, travel from one object to another via facilities such as hyperlinks and URL addresses. The Web is an ever-growing body of hypertext and multimedia documents. As of 2008, Google had discovered 1 trillion Web pages. The Internet Archive, which makes regular copies of many publicly available Web pages and media files, was three petabytes in size as of March 2009. Several billions of pages are added each day to that number. As the information offered in the Web grows daily, obtaining that information becomes more and more tedious. The main difficulty lies in the semi-structured or unstructured Web content that is not easy to regulate and where enforcing a structure or standards is difficult. A set of Web pages lacks a unifying structure and shows far more authoring styles and content variation than that seen in traditional print document collections. This level of complexity makes an “off-the-shelf” database-management and information-retrieval solution very complex and almost impossible to use. New methods and tools are necessary. Web mining may be defined as the use of data-mining techniques to automatically discover and extract information from Web documents and services. It refers to the overall process of discovery, not just to the application of standard data-mining tools. Some authors suggest decomposing Web-mining task into four subtasks:
1.
Resource Finding.
This is the process of retrieving data, which is either online or offline, from the multimedia sources on the Web, such as news articles, forums, blogs, and the text content of HTML documents obtained by removing the HTML tags.
2.
Information Selection and Preprocessing.
This is the process by which different kinds of original data retrieved in the previous subtask is transformed. These transformations could be either a kind of preprocessing such as removing stop words and stemming or a preprocessing aimed at obtaining the desired representation, such as finding phrases in the training corpus and representing the text in the first-order logic form.
3.
Generalization.
Generalization is the process of automatically discovering general patterns within individual Web sites as well as across multiple sites. Different general-purpose machine-learning techniques, data-mining techniques, and specific Web-oriented methods are used.
4.
Analysis.
This is a task in which validation and/or interpretation of the mined patterns is performed.
There are three factors affecting the way a user perceives and evaluates Web sites through the data-mining process: (1) Web-page content, (2) Web-page design, and (3) overall site design including structure. The first factor is concerned with the goods, services, or data offered by the site. The other factors are concerned with the way in which the site makes content accessible and understandable to its users. We distinguish between the design of individual pages and the overall site design, because a site is not a simply a collection of pages; it is a network of related pages. The users will not engage in exploring it unless they find its structure simple and intuitive. Clearly, understanding user-access patterns in such an environment will not only help improve the system design (e.g., providing efficient access between highly correlated objects, better authoring design for WWW pages), it will also lead to better marketing decisions. Commercial results will be improved by putting advertisements in proper places, better customer/user classification, and understanding user requirements better through behavioral analysis.
No longer are companies interested in Web sites that simply direct traffic and process orders. Now they want to maximize their profits. They want to understand customer preferences and customize sales pitches to individual users. By evaluating a user’s purchasing and browsing patterns, e-vendors want to serve up (in real time) customized menus of attractive offers e-buyers cannot resist. Gathering and aggregating customer information into e-business intelligence is an important task for any company with Web-based activities. e-Businesses expect big profits from improved decision making, and therefore e-vendors line up for data-mining solutions.
Borrowing from marketing theory, we measure the efficiency of a Web page by its contribution to the success of the site. For an online shop, it is the ratio of visitors that purchased a product after visiting this page to the total number of visitors that accessed the page. For a promotional site, the efficiency of the page can be measured as the ratio of visitors that clicked on an advertisement after visiting the page. The pages with low efficiency should be redesigned to better serve the purposes of the site. Navigation-pattern discovery should help in restructuring a site by inserting links and redesigning pages, and ultimately accommodating user needs and expectations.
To deal with problems of Web-page quality, Web-site structure, and their use, two families of Web tools emerge. The first includes tools that accompany the users in their navigation, learn from their behavior, make suggestions as they browse, and, occasionally, customize the user profile. These tools are usually connected to or built into parts of different search engines. The second family of tools analyzes the activities of users offline. Their goal is to provide insights into the semantics of a Web site’s structure by discovering how this structure is actually utilized. In other words, knowledge of the navigational behavior of users is used to predict future trends. New data-mining techniques are behind these tools, where Web-log files are analyzed and information is uncovered. In the next four sections, we will illustrate Web mining with four techniques that are representative of a large spectrum of Web-mining methodologies developed recently.
11.2 WEB CONTENT, STRUCTURE, AND USAGE MINING
One possible categorization of Web mining is based on which part of the Web one mines. There are three main areas of Web mining: Web-content mining, Web-structure mining, and Web-usage mining. Each area is classified by the type of data used in the mining process. Web-content mining uses Web-page content as the data source for the mining process. This could include text, images, videos, or any other type of content on Web pages. Web-structure mining focuses on the link structure of Web pages. Web-usage mining does not use data from the Web itself but takes as input data recorded from the interaction of users using the Internet.
The most common use of Web-content mining is in the process of searching. There are many different solutions that take as input Web-page text or images with the intent of helping users find information that is of interest to them. For example, crawlers are currently used by search engines to extract Web content into the indices that allow immediate feedback from searches. The same crawlers can be altered in such a way that rather than seeking to download all reachable content on the Internet, they can be focused on a particular topic or area of interest.
To create a focused crawler, a classifier is usually trained on a number of documents selected by the user to inform the crawler as to the type of content to search for. The crawler will then identify pages of interest as it finds them and follow any links on that page. If those links lead to pages that are classified as not being of interest to the user, then the links on that page will not be used further by the crawler.
Web-content mining can also be seen directly in the search process. All major search engines currently use a list-like structure to display search results. The list is ordered by a ranking algorithm behind the scenes. An alternative view of search results that has been attempted is to provide the users with clusters of Web pages as results rather than individual Web pages. Often a hierarchical clustering that will give multiple topic levels is performed.
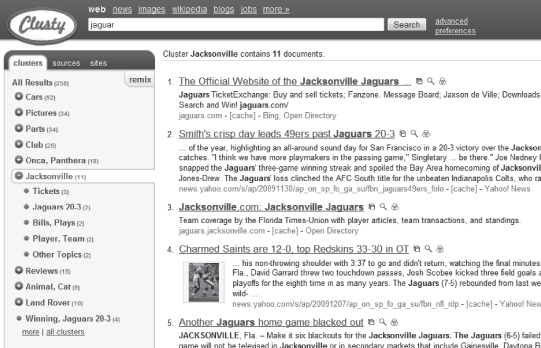
As an example consider the Web site Clusty.com, which provides a clustered view of search results. If one keyword were to enter [jaguar] as a search onto this Web site, one sees both a listing of topics and a list of search results side-by-side, as shown in Figure
11.1
. This specific query is ambiguous, and the topics returned show that ambiguity. Some of the topics returned include: cars, Onca, Panthery (animal kingdom), and Jacksonville (American football team). Each of these topics can be expanded to show all of the documents returned for this query in a given topic.
Figure 11.1.
Example query from Clusty.com.
Web-structure mining considers the relationships between Web pages. Most Web pages include one or more hyperlinks. These hyperlinks are assumed in structure mining to provide an endorsement by the linking page of the page linked. This assumption underlies PageRank and HITS, which will be explained later in this section.
Web-structure mining is mainly used in the information retrieval (IR) process. PageRank may have directly contributed to the early success of Google. Certainly the analysis of the structure of the Internet and the interlinking of pages currently contributes to the ranking of documents in most major search engines.
Web-structure mining is also used to aid in Web-content mining processes. Often, classification tasks will consider features from the content of the Web page and may consider the structure of the Web pages. One of the more common features in Web-mining tasks taken from structure mining is the use of anchor text. Anchor text refers to the text displayed to users on an HTML hyperlink. Oftentimes the anchor text provides summary keywords not found on the original Web page. The anchor text is often as brief as search-engine queries. Additionally, if links are endorsements of Web pages, then the anchor text offers keyword-specific endorsements.
Web-usage mining refers to the mining of information about the interaction of users with Web sites. This information may come from server logs, logs recorded by the client’s browser, registration form information, and so on. Many usage questions exist, such as the following: How does the link structure of the Web site differ from how users may prefer to traverse the page? Where are the inefficiencies in the e-commerce process of a Web site? What segments exist in our customer base?
There are some key terms in Web-usage mining that require defining. A “visitor” to a Web site may refer to a person or program that retrieves a Web page from a server. A “session” refers to all page views that took place during a single visit to a Web site. Sessions are often defined by comparing page views and determining the maximum allowable time between page views before a new session is defined. Thirty minutes is a standard setting.
Web-usage mining data often requires a number of preprocessing steps before meaningful data mining can be performed. For example, server logs often include a number of computer visitors that could be search-engine crawlers, or any other computer program that may visit Web sites. Sometimes these “robots” identify themselves to the server passing a parameter called “user agent” to the server that uniquely identifies them as robots. Some Web page requests do not make it to the Web server for recording, but instead a request may be filled by a cache used to reduce latency.
Servers record information on a granularity level that is often not useful for mining. For a single Web-page view, a server may record the browsers’ request for the HTML page, a number of requests for images included on that page, the Cascading Style Sheets (CSS) of a page, and perhaps some JavaScript libraries used by that Web page. Often there will need to be a process to combine all of these requests into a single record. Some logging solutions sidestep this issue by using JavaScript embedded into the Web page to make a single request per page view to a logging server. However, this approach has the distinct disadvantage of not recording data for users that have disabled JavaScript in their browser.
Web-usage mining takes advantage of many of the data-mining approaches available. Classification may be used to identify characteristics unique to users that make large purchases. Clustering may be used to segment the Web-user population. For example, one may identify three types of behavior occurring on a university class Web site. These three behavior patterns could be described as users cramming for a test, users working on projects, and users consistently downloading lecture notes from home for study. Association mining may identify two or more pages often viewed together during the same session, but that are not directly linked on a Web site. Sequence analysis may offer opportunities to predict user navigation patterns and therefore allow for within site, targeted advertisements. More on Web-usage mining will be shown through the LOGSOM algorithm and through the section on “Mining path traversal patterns.”