Mathematics and the Real World (35 page)
Read Mathematics and the Real World Online
Authors: Zvi Artstein

- We choose a
sample space
, which we will call
Ω
. This is an arbitrary set whose members are called
trials
or
samples
. - We select a collection of sets, all of which are partial sets of the sample space
Ω
. We will denote this collection of sets
Σ
, and the sets within it we will call
events
. The family of sets
Σ
has several properties: the set
Ω
is within it (i.e.,
Ω
is an event). If a sequence of sets (i.e., events) is within it, then the union of these events is also within it. If an event is in the collection, also its complement, that is,
Ω
minus the event, is an event. - For the collection of events we will define a
probability function
, which we will denote
P
. This assigns to each event a number between 0 and 1 (called the probability of the event). This function has the property that the probability of the union of a sequence of events that are pairwise disjoint is the sum of the probability of the individual events. Also, the probability of event
Ω
is 1.
For those unfamiliar with the jargon or terminology of mathematics, we will state that two events (two sets) are disjoint if there is no trial (member in
Ω
) that is in both events. The union of two sets is the set that includes the members of both sets. Thus, the second axiom says, among other things, that the set that contains the trials in both events is itself an event.
There is a reason for the statement that the collection of sets
Σ
of the events does not necessarily contain all the partial sets of the sample space
Ω
. The reason is essentially technical, and there is no need to understand it in order to follow the rest of the explanation. (The reason is that when
Σ
consists of all the subsets, it may be impossible, when the sample set is infinite, to find a probability function that fulfills the requirement of the third axiom.)
One of the innovative features of the axioms is that they ignore the question of how the probabilities are created. The axioms assume that the
probabilities exist and merely requires that they have certain properties that common sense indicates. Following the Greek method, when you try to analyze a certain situation, you must identify the sample space that satisfies the axioms and describes the situation. If your identification is accurate, you can continue, and with the help of mathematics you can arrive at correct conclusions. Kolmogorov went further than the Greeks, however. They claimed that the “right” axioms were determined according to the state of nature. Kolmogorov allows completely different spaces to be constructed for the same probability scenario. An example follows.
The framework defined by the system of axioms enables a proper mathematical analysis to be performed. For instance, we wish to calculate the probability of an event
B
in a sample space that includes only partial events of event
A
, which has a probability of
P
(
A
). This new probability of
B
will be equal to the probability of that part of
B
that is in common with
A
(we are concerned only with that part of
B
) divided by the probability that
A
occurs. This can be written as the following formula. Denote the part that is common to
A
and
B
by
B
∩
A
, called
A
intersect
B
. Then the probability of the partial event of
B
that is in
A
is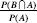 . This is called the
. This is called the
conditional probability
. The two events are
independent
if it is impossible to draw any conclusions regarding the existence of the second event from the existence of one of them, even a probabilistic conclusion. The mathematical formulation of independence states that the updated probability of
B
equals its original probability, or
P
(
B
∩
A
) =
P
(
A
)
P
(
B
). We have obtained a mathematical definition of independence. The same can be done with respect to other concepts used in probability theory.
This is an appropriate place for a warning: Many texts refer to the expressionfor conditional probability as the probability of
B given A
. This in turn leads to the interpretation of the conditional probability as the updated probability of
B
when one is
informed
that
A
has occurred. Such an interpretation may lead, as we shall see later, to errors when applying the formulae. While in plain language the two expressions, given and informed, are not that different, in applications, when we are informed of an event, the circumstances in which the information is revealed should be taken into account. When we are informed that
A
has occurred, we can by no means automatically conclude that the conditional probability of
B
given
A
depicts the updated probability of
B
.
And now we present, as promised, the formula for Bayes's theorem (this can be skipped without rendering the text that follows it less understandable). Assume that we know that event
A
has occurred, and we wish to learn from that the chances that event
B
will occur. For the sake of the example we assume the conditional probability, which we denote as
P
(
B
│
A
), describes the desired probability of
B
when we know that
A
has occurred. Bayes's formula as we described it verbally in the previous section is
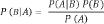
Moreover, as we explained above,
P
(
A
│
B
) is
P
(
B
∩
A
) divided by
P
(
B
). (If we wish to conform with the wording of the principle as displayed in the previous section, we should write the denominator as
P
(
A
│
B
)
P
(
B
) +
P
(
A
│
~B
)
P
(
~B
) where
~B
indicates the event
B
does not occur. (This is the way most texts write it.) Does that sound complicated? Perhaps so, but the framework provides a proper mathematical basis for the analysis of randomness.
Notice the assumption we made: The circumstances are such that
P
(
B
│
A
) is the correct updated probability. Otherwise we should resort to the original Bayes's scheme as described in the previous section, namely, we should calculate the ratio of the probability that
A
has occurred when we are informed that
B
has occurred to the entire probability that we are informed that
A
has occurred. In many applications the assumption does not hold, that is, the probability that we are informed that
A
has occurred is not
P
(
A
).
The above framework provides an outline for the construction of probabilities, but the events that appear in the axioms do not necessarily have significance in reality, significance that we can identify or calculate. Take as an example one toss of a coin. The sample space may be made up of two symbols, say
a
and
b
, with equal probabilities. If we declare that if
a
occurs this means (note that this is
our
explanation!) that the coin falls with heads showing, and if
b
comes up in the sample it means that the coin fell with tails uppermost, we have a model for one flip of the coin. We cannot analyze two consecutive tosses of the coin in the framework of this sample space because there are four possible outcomes of two flips of the coin. For that case we have to construct another sample space. To arrive at a model that permits multiple flips of the coin, the sample space has to increase. To enable any number of tosses of the coin, we will require an infinite sample space. The technical details will interest those who deal with the mathematics (and students), and we will not present them here. We will just say that in a sample space in which an infinite series of flips of the coin can take place, events occur the probability of which is zero.
This is certainly intuitive. A ball spinning on a continuous circle stops at a point. The chances of its stopping on a predetermined point is zero, but the chance of its stopping on a collection of points, for example, on a complete
segment, is not zero. With this end in view, Kolmogorov used mathematics that had been developed for other purposes and that explained how it was possible for a section to have a length while it consists of points the length of each of which is zero; the explanation had not been available to the Greeks when they encountered a similar problem. Furthermore, Kolmogorov's model can be used to explain and prove Bernoulli's weak law of large numbers (see the previous section), and even to formulate and prove a stronger law, as follows. We will perform a series of flips of a coin. These can create many series of results. We will examine those series of outcomes in which the proportion of the number of heads to the total number of throws does not approach 50 percent as the number of throws increases. This set of series, says
the strong law of large numbers
, has a probability of zero. (The careful reader whose mathematical education included Kolmogorov's theory will have noticed that although that event has zero probability, it can nevertheless occur. Indeed, there could be samples in which the proportion does not approach a half, but these are negligible.)