Pro Oracle Database 11g Administration (49 page)

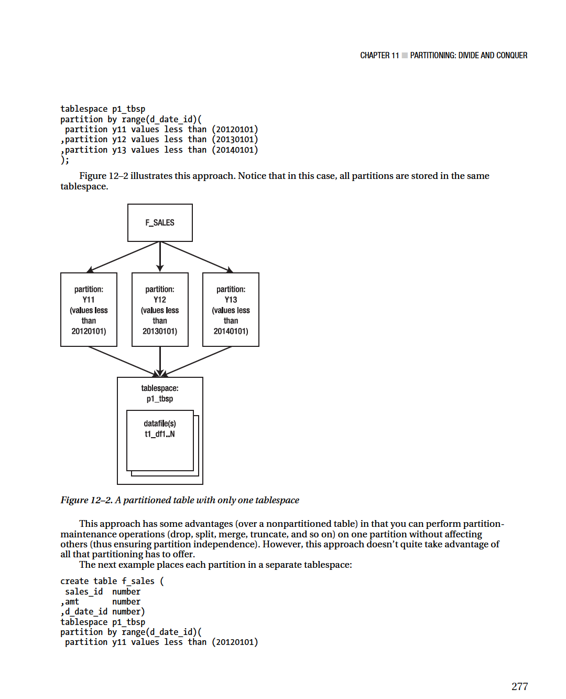
CHAPTER 11 ■ PARTITIONING: DIVIDE AND CONQUER
create table f_sales (
sales_id number
,amt number
,d_date_id number)
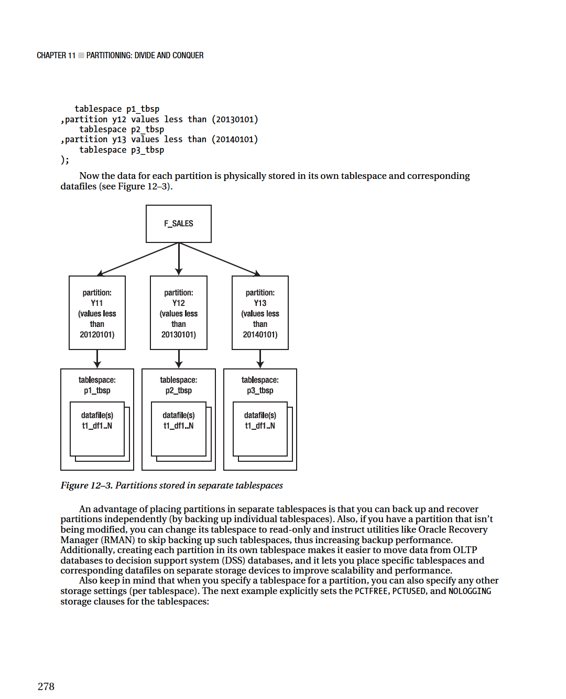
tablespace p1_tbsp
partition by range(d_date_id)(
partition y11 values less than (20120101)
tablespace p1_tbsp pctfree 5 pctused 90 nologging
,partition y12 values less than (20130101)
tablespace p2_tbsp pctfree 5 pctused 90 nologging
,partition y13 values less than (20140101)
tablespace p3_tbsp pctfree 5 pctused 90 nologging
);
Partitioning by List
List partitioning works well for partitioning unordered and unrelated sets of data. For example, say you have a large table and want to partition it by state codes. To do so, use the PARTITION BY LIST clause of the CREATE TABLE statement. This example uses state codes to create three list-based partitions: create table f_sales
(reg_sales number
,d_date_id number
,state_code varchar2(20)
)
partition by list (state_code)
( partition reg_west values ('AZ','CA','CO','MT','OR','ID','UT','NV')
,partition reg_mid values ('IA','KS','MI','MN','MO','NE','OH','ND')
,partition reg_rest values (default)
);
The partition key for a list-partitioned table can be only one column. Use the DEFAULT list to specify a partition for rows that don’t match values in the list. If you don’t specify a DEFAULT list, then an error is generated when a row is inserted with a value that doesn’t map to the defined partitions. Run this SQL
statement to view list values for each partition:
select
table_name
,partition_name
,high_value
from user_tab_partitions
where table_name = 'F_SALES'
order by 1;
Here’s the output for this example:
TABLE_NAME PARTITION_ HIGH_VALUE
---------- ---------- --------------------------------------------------
F_SALES REG_MID 'IA', 'KS', 'MI', 'MN', 'MO', 'NE', 'OH', 'ND'
F_SALES REG_REST default
F_SALES REG_WEST 'AZ', 'CA', 'CO', 'MT', 'OR', 'ID', 'UT', 'NV'
279
CHAPTER 11 ■ PARTITIONING: DIVIDE AND CONQUER
The HIGH_VALUE column displays the list values defined for each partition. This column is of data type LONG. If you’re using SQL*Plus, you may need to set the LONG variable to a value higher than the default (80 bytes), to display the entire contents of the column:
SQL> set long 1000
Partitioning by Hash
Sometimes a large table doesn’t contain an obvious column by which to partition the table, whether by range or by list. For example, suppose you have a table to store census data. Each person entered into the table has a government-assigned unique number (such as a Social Security Number in the US). In this scenario, you have a somewhat random primary key that doesn’t follow a distinct pattern. This table is a candidate for partitioning by hash because it doesn’t fit well into a range- or list-partitioning scheme.
Hash partitioning maps rows to partitions based on an internal algorithm that spreads data evenly across all defined partitions. You don’t have any control over the hashing algorithm or how Oracle distributes the data. You specify how many partitions you’d like, and Oracle divides the data evenly based on the hash-key column.
To create hash-based partitions, use the PARTITION BY HASH clause of the CREATE TABLE statement.
This example creates a table that is divided into three partitions; each partition is created in its own tablespace:
create table browns(
brown_id number
,bear_name varchar2(30))
partition by hash(brown_id)
partitions 3
store in(tbsp1, tbsp2, tbsp3);
Of course, you have to modify details like the tablespace names to match those in your environment. Alternatively, you can eliminate the STORE IN clause, and Oracle places all partitions in your default tablespace. If you want to name both the tablespaces and partitions, you can specify them as follows:
create table browns(
brown_id number
,bear_name varchar2(30))
partition by hash(brown_id)
(partition p1 tablespace tbsp1
,partition p2 tablespace tbsp2
,partition p3 tablespace tbsp3);
Hash partitioning has some interesting performance implications. All rows that share the same value for the hash key are inserted into the same partition. This means inserts are particularly efficient, because the hashing algorithm ensures that the data is distributed uniformly across partitions. Also, if you typically select for a specific key value, Oracle has to access only one partition to retrieve those rows.
However, if you search by ranges of values, Oracle will most likely have to search every partition to determine which rows to retrieve. Thus range searches can perform poorly in hash-partitioned tables.
280
CHAPTER 11 ■ PARTITIONING: DIVIDE AND CONQUER
Blending Different Partitioning Methods
Oracle allows you to partition a table using multiple strategies (
composite partitioning
). Suppose you have a table that you want to partition on a number range, but you also want to subdivide each partition by a list of regions. The following example does just that:
create table f_sales(
sales_amnt number
,reg_code varchar2(3)
,d_date_id number
)
partition by range(d_date_id)
subpartition by list(reg_code)
(partition p2010 values less than (20110101)
(subpartition p1_north values ('ID','OR')
,subpartition p1_south values ('AZ','NM')
),
partition p2011 values less than (20120101)
(subpartition p2_north values ('ID','OR')
,subpartition p2_south values ('AZ','NM')
)
);
You can view subpartition information by running the following query: select
table_name
,partitioning_type
,subpartitioning_type
from user_part_tables
where table_name = 'F_SALES';
Here’s some sample output:
TABLE_NAME PARTITION SUBPART
-------------------- --------- -------
F_SALES RANGE LIST
Run the next query to view information about the subpartitions:
select
table_name
,partition_name
,subpartition_name
from user_tab_subpartitions
where table_name = 'F_SALES'
order by
table_name
,partition_name;
281
CHAPTER 11 ■ PARTITIONING: DIVIDE AND CONQUER
Here’s a snippet of the output:
TABLE_NAME PARTITION_NAME SUBPARTITION_NAME
-------------------- -------------------- --------------------
F_SALES P2010 P1_SOUTH
F_SALES P2010 P1_NORTH
F_SALES P2011 P2_SOUTH
F_SALES P2011 P2_NORTH
Prior to Oracle Database 11
g
, composite partitioning can be implemented as range-hash (available since version 8
i
) and range-list (available since version 9
i
). Starting with Oracle Database 11
g
, here are the composite partitioning strategies available:
•
Range-hash (8
i
):
Appropriate for ranges that can be subdivided by a somewhat random key, like ORDER_DATE and CUSTOMER_ID.
•
Range-list (9
i
):
Useful when a range can be further partitioned by a list, such as SHIP_DATE and STATE_CODE.
•
Range-range:
Appropriate when you have two distinct partition range values, like ORDER_DATE and SHIP_DATE.
•
List-range:
Useful when a list can be further subdivided by a range, like REGION
and ORDER_DATE.
•
List-hash:
Useful for further partitioning a list by a somewhat random key, such as STATE_CODE and CUSTOMER_ID.
•
List-list:
Appropriate when a list can be further delineated by another list, such as COUNTRY_CODE and STATE_CODE.
As you can see, composite partitioning gives you a great deal of flexibility in the way you partition your data.
Creating Partitions on Demand
As of Oracle Database 11
g,
you can instruct Oracle to automatically add partitions to range-partitioned tables. The feature is known as
interval partitioning
. Oracle dynamically creates a new partition when data inserted exceeds the maximum bound of the range-partitioned table. The newly added partition is based on an interval that you specify (hence the name
interval partitioning
).
Suppose you have a range-partitioned table and want Oracle to automatically add a partition when values are inserted above the highest value defined for the highest range. You can use the INTERVAL
clause of the CREATE TABLE statement to instruct Oracle to automatically add a partition to the high end of a range-partitioned table.
The following example creates a table that initially has one partition with a high-value range of 01-JAN-2012:
create table f_sales(
sales_amt number
,d_date date
)
partition by range (d_date)
interval(numtoyminterval(1, 'YEAR'))
store in (p1_tbsp, p2_tbsp, p3_tbsp)
(partition p1 values less than (to_date('01-jan-2012','dd-mon-yyyy')) tablespace p1_tbsp);
282
CHAPTER 11 ■ PARTITIONING: DIVIDE AND CONQUER
The first partition is created in P1_TBSP. As Oracle adds partitions, it assigns a new partition to the tablespaces defined in the STORE IN clause (it’s supposed to store them in a round-robin fashion, but isn’t always consistent).
■
Note
With interval partitioning, you can specify only a single key column from the table, and it must be either a DATE or a NUMBER data type.
The interval in this example is one year, specified by the INTERVAL(NUMTOYMINTERVAL(1, 'YEAR')) clause. If a record is inserted into the table with a D_DATE value greater than or equal to 01-JAN-2012, Oracle automatically adds a new partition to the high end of the table. You can check the details of the partition by running this SQL statement:
select
table_name
,partition_name
,partition_position
,tablespace_name
,high_value
from user_tab_partitions
where table_name = 'F_SALES'
order by
table_name
,partition_position;
Here’s some sample output (the column headings have been shortened and the HIGH_VALUE
column has been cut short so the output fits on the page):
TABLE_NAME PARTITION_ Part. Pos TABLESPACE HIGH_VALUE
---------- ---------- --------- ---------- ------------------------------
F_SALES P1 1 P1_TBSP TO_DATE(' 2012–01-01 00:00:00'
Now, insert data above the high value for the highest partition:
SQL> insert into f_sales values(1,sysdate+1000);
Here’s what the output from selecting from USER_TAB_PARTITIONS now shows: TABLE_NAME PARTITION_ Part. Pos TABLESPACE HIGH_VALUE
---------- ---------- --------- ---------- ------------------------------
F_SALES P1 1 P1_TBSP TO_DATE(' 2012–01-01 00:00:00'
F_SALES SYS_P476 2 P3_TBSP TO_DATE(' 2014-01-01 00:00:00'
A partition named SYS_P476 was automatically created with a high value of 2014-01-01. If you don’t like the name that Oracle gives the partition, you can rename it:
SQL> alter table f_sales rename partition sys_p476 to p2;
Notice what happens when a value is inserted that falls into a year interval between the two partitions:
SQL> insert into f_sales values(1,sysdate+500);
283
CHAPTER 11 ■ PARTITIONING: DIVIDE AND CONQUER
Querying the USER_TAB_PARTITIONS table shows that another partition has been created because the value inserted falls into a year interval that isn’t included in the existing partitions: TABLE_NAME PARTITION_ Part. Pos TABLESPACE HIGH_VALUE