Whole (17 page)
Authors: T. Colin Campbell

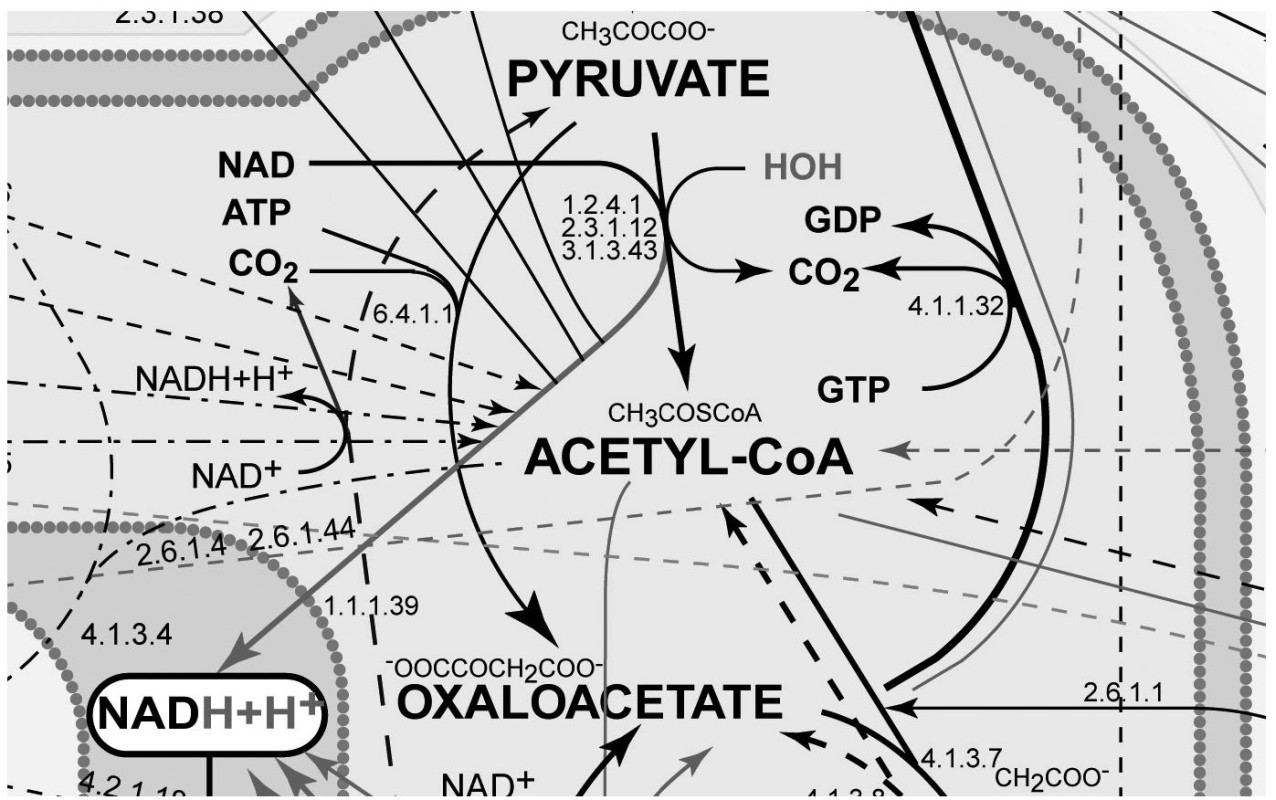
FIGURE 7-3.
Expanded inset of
Figure 7-2
I emphasize this metabolic complexity so you can see just how impossible it is to fully understand the way our bodies react to the foods we eat and the nutrients they contain. Explaining nutrient function by only one or even a couple of these reactions is not sufficient. Once consumed, nutrients interact with one another and with other food-borne chemicals within an enormous maze of metabolic reactions located in these hundred trillion cells. No single reaction or single mechanism accounts for an individual nutrient’s effect. Every nourishing nutrient and related food chemical enters cellular metabolism and gets metabolized into multiple products via highly integrated pathways just as complex as those as shown in
Figures 7-1 to 7-3
.
The fact that each nutrient passes through such a maze of reaction pathways suggests that each nutrient also is likely to participate in multiple health and disease outcomes. The one nutrient/one disease relationship implied by reductionism, although widely popular, is simply incorrect. Every nutrient-like chemical that enters this complex system of reactions creates a rippling effect that may extend far into the pool of metabolism. And with every bite of food we eat, there are tens and probably hundreds of thousands of food chemicals entering this metabolism pool more or less simultaneously.
Metabolism
is the sum total of all the chemical reactions in the body that sustain life. When you think of the billions of reactions that occur all the time, you might wonder how we have enough energy in our bodies to get
anything else done. After all, every one of those chemical reactions requires energy. And since one of the main outputs of metabolism is usable energy for the body, it’s crucial that the energy produced be greater—by a wide margin—than the energy expended to produce it. Fortunately, we’ve evolved molecules whose main job is to significantly lower the energy required for chemical reactions within the body. These molecules are called
enzymes.
I used enzymes, earlier, to help explain why a part cannot be fully understood outside the context of its system as a whole, an idea that should become even more clear as we look further at the role they play in the body. Enzymes are large protein molecules, present in all our cells, that, through a series of reactions, turn one thing (say, a sugar molecule), called a
substrate
, into another (say, a glucose-related chemical the body uses to synthesize fat), called a
product
or
metabolite.
Think of enzymes as large, fully-automated factories. Imagine inserting a small log (the substrate) into one end of a huge factory building and, at the exit end, collecting a nicely designed salad bowl (the product). You could turn the log into a salad bowl by hand, of course, but it would require much more time and labor. The factory dramatically increases the efficiency of the transformation. Enzymes do the same inside cells, converting substrates into products very quickly while using very little energy. The reactions enzymes cause (the word biologists use is that they
catalyze
reactions) rarely, if ever, occur without the assistance of an enzyme. If they do, the rate of reaction—the speed with which the reaction occurs—is a minuscule fraction of what is possible when an enzyme is involved, and the amount of energy required is much higher.
Comparatively speaking, enzymes are very large. An enzyme molecule might be 10,000 to 20,000 times the size of a substrate molecule that it processes—hence the visual of the factory and the log.
Figure 7-4
shows a substrate, A, being converted to a product, B. But most reactions do not occur in isolation. They connect with follow-on reactions, like the one in
Figure 7-4
where B (now the substrate) is converted to C (the new product). Enzyme 1 converts A to B, while enzyme 2 converts B to C.
A given enzyme can function at different levels of potency based on supply (the amount of substrate available) and demand (the amount of product already in the cell). Just as factory assembly lines can move quickly or slowly based on the supply of raw materials and the demand for finished goods, enzymes adjust the speed at which they convert substrate
to product (known in the trade as its
activity).
In fact, an enzyme can even reverse reactions to return a product to its substrate. In short, enzymes control whether reactions occur and, if so, how fast and in which direction.
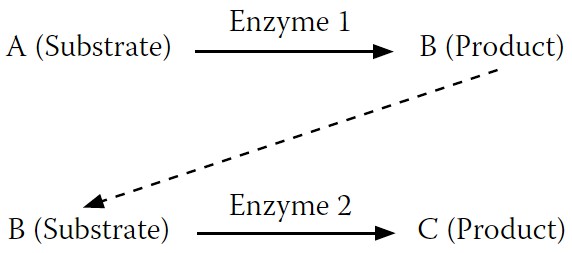
FIGURE 7-4.
A simple enzyme reaction
When they initially form, enzymes appear as linear chains of amino acids, carefully arranged in sequences dictated by DNA. But because amino acids have chemical and physical affinities for each other, the chain folds onto itself (as in
Figure 7-5
), creating a three-dimensional shape the same way a very long string of magnetic beads might.

FIGURE 7-5.
Computer-developed model of the enzyme cyclic ADP ribose hydrolase (CD38)
This folding gives enzymes one way to vary their activity: they simply change shape. This enzymatic shapeshifting is crucial because it changes the enzyme’s chemical and physical properties in ways that alter its ability to modify reaction rates. Many scientists who study enzymes wax poetic about the incomprehensible speed with which enzymes configure themselves to perform their tasks. Here’s a typical entry, from the
New World Encyclopedia:
For an enzyme to be functional, it must fold into a precise threedimensional shape. How such a complex folding can take place remains a mystery. A small chain of 150 amino acids making up an enzyme has an extraordinary number of possible folding configurations: if it tested 1,012 different configurations every second, it would take about 1,026 years to find the right one.... Yet, a denatured enzyme can refold within fractions of a second and then precisely react in a chemical reaction.... [I]t demonstrates a stunning complexity and harmony in the universe.
21
The author cites numbers for a relatively small (by enzyme standards) hypothetical molecule in his attempt to describe the indescribable. The rapidity with which an enzyme responds (from a limp linear chain to a precise glob ready to do its business, in fractions of a second) is phenomenal. The chemical variety of substrates that can be metabolized by a single active enzyme is likewise phenomenal. And the large number of factors capable of modifying enzyme structure, amount, and activity is equally phenomenal.
Inherent in this discussion is the intimate connection between nutrient metabolism and the world of enzymes. Enzyme-catalyzed reactions, infinite in number and infinitely networked, are controlled by nutrients and related compounds, which also are infinite in number. Although nutrients control enzymes, enzymes also act
on
nutrients to manufacture endless products that are then used in the body as well as for the proper functioning of the body.
Which brings us, finally, back to MFO and the role it plays in cancer formation.
Unavoidably, I’ve had to summarize, truncate, and simplify our research and findings here—the topic is just too extensive and too technical to explain in a single chapter. My goal here, after all, is not to turn you into an MFO expert. Rather, in sharing the tale of my fifty-plus-year research journey with MFO, I hope to give you a better understanding of how animal protein affects cancer formation, and a deeper appreciation of how the complexity of MFO eloquently testifies to a wholistic, not reductionist, view of nutrition and health.
MFO is a particularly complex enzyme that metabolizes many chemicals, some normally present in the body and others the body might never have encountered previously. Located largely but not exclusively in the liver, MFO metabolizes steroid-type hormones (e.g., sex hormones like estrogens and androgens, and stress hormones), fatty acids (i.e., precursors to chemicals that support the immune and neurological systems), and cholesterol (involved in cardiovascular disease and the building of cell membranes), among other chemicals, into substances that are closer to the state in which our bodies will ultimately use them. MFO also detoxifies foreign chemicals, rendering them capable of being readily excreted in the urine.
Very early in my research career I was taught that AF (like other carcinogens) is converted by the MFO enzyme to a less toxic metabolite that is excreted in the urine and feces, as is shown in
Figure 7-6
.
But this model was clearly too simple. For one thing, the Indian researchers I mentioned earlier, who in 1968 published their finding that a high-protein (20 percent) diet increased AF-initiated liver tumors in rats,
22
previously had shown that this same high-protein diet actually decreased the immediate toxicity of AF when it is administered at very high doses.
23
The results were a paradox that the traditional model of AF metabolism didn’t account for.
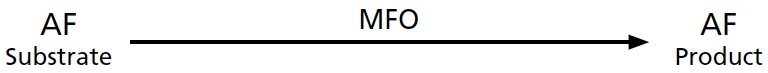
FIGURE 7-6.
Presumed model for MFO conversion of AF
Suspecting MFO as the key to resolving this paradox, my lab started by establishing that the high-protein diet increased MFO enzyme activity in rats,
24
meaning that the more dietary protein the rat consumed, the faster AF (specifically, the parent substrate, AFB1) was detoxified. This was the finding that made sense, but it ran counter to the Indian researchers’ observation
25
that cancer
increased
with a high-protein diet.
One possibility we considered was that the MFO enzyme might be producing two kinds of metabolites: one that was less toxic than AF and safely excreted, and one that was more toxic than AF that gave rise to cancer. But why would an enzyme do such a strange and contradictory thing? Even though it seems strange, it was a real possibility in our minds; for a long time, before this and before the MFO enzyme was discovered, scientists thought that many chemical carcinogens initiated cancer only after they were “activated” by enzymes, and so a chemical like AF producing a more toxic metabolite sounded very possible.