Data Mining (104 page)
Authors: Mehmed Kantardzic

Figure 12.29.
A variogram-cloud technique discovers an outlier.
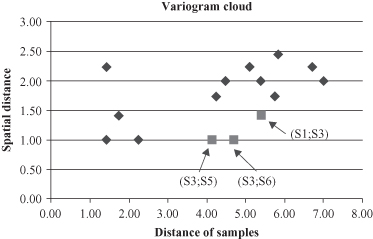
Computation of spatial distances and distances of samples, as a part of a variogram technique, shows that there is a sample spatially relatively close to a group of other samples (small space distances) but with very high distances in other nonspatial attributes. This is the sample S3, which is spatially close to samples S1, S5, and S6. Coordinates of these samples and corresponding distances are given in Figure
12.28
b, selecting S3 as a candidate for an outlier. Visualization of these and other relations between samples through a variogram shows the same results.
12.4 DISTRIBUTED DATA MINING (DDM)
The emergence of tremendous data sets creates a growing need for analyzing them across geographical lines using distributed systems. These developments have created unprecedented opportunities for a large-scale data-driven knowledge discovery, as well as the potential for fundamental gains in scientific and business understanding. Implementations of data-mining techniques on high-performance distributed computing platforms are moving away from centralized computing models for both technical and organizational reasons. In some cases, centralization is hard because it requires these multi-terabyte data sets to be transmitted over very long distances. In others, centralization violates privacy legislation, exposes business secrets, or poses other social challenges. Common examples of such challenges arise in medicine, where relevant data might be spread among multiple parties, in commercial organizations such as drug companies or hospitals, government bodies such as the U.S. Food and Drug Administration, and nongovernment organizations such as charities and public-health organizations. Each organization is bound by regulatory restrictions, such as privacy legislation, or corporate requirements on proprietary information that could give competitors a commercial advantage. Consequently, a need exists for developing algorithms, tools, services, and infrastructure that let us mine data distributed across organizations while preserving privacy.
This shift toward intrinsically distributed, complex environments has prompted a range of new data-mining challenges. The added dimension of distributed data significantly increases the complexity of the data-mining process. Advances in computing and communication over wired and wireless networks have resulted in many pervasive distributed computing environments. Many of these environments deal with different distributed sources of voluminous data, multiple compute nodes, and distributed user community. Analyzing and monitoring these distributed data sources require a new data-mining technology designed for distributed applications. The field of DDM deals with these problems—mining distributed data by paying careful attention to the distributed resources. In addition to data being distributed, the advent of the Internet has led to increasingly complex data, including natural-language text, images, time series, sensor data, and multi-relational and object data types. To further complicate matters, systems with distributed streaming data need incremental or online mining tools that require a complete process whenever a change is made to the underlying data. Data-mining techniques involved in such a complex environment must encounter great dynamics due to changes in the system, and it can affect the overall performance of the system. Providing support for all these features in DDM systems requires novel solutions.
The Web architecture, with layered protocols and services, provides a sound framework for supporting DDM. The new framework embraces the growing trend of merging computation with communication. DDM accepts the fact that data may be inherently distributed among different loosely coupled sites, often with heterogeneous data, and connected by a network. It offers techniques to discover new knowledge through distributed data analysis and modeling using minimal communication of data. Also, interactions in a distributed system need to be implemented in a reliable, stable, and scalable way. Ultimately, systems must be able to hide this technological complexity from users.
Today, the goods that are able to be transacted through e-services are not restricted to real entities such as electronics, furniture, or plane tickets. The Internet and the WWW evolve to include also resources such as software, computation abilities, or useful data sets. These new resources are potentially able to be sold or rented to clients as services for Internet users. Data mining is emerging as intuitively suitable for being delivered as an e-service because the approach reduces the high cost of setting up and maintaining infrastructure of supporting technologies. To efficiently and effectively deliver data mining as a service in the WWW, Web-service technologies are introduced to provide layers of abstractions and standards above existing software systems. These layers are capable of bridging any operating system, hardware platform, or programming language, just as the Web does. The natural extension for these services is grid computing. The grid is a distributed computing infrastructure that enables coordinated resource sharing within dynamic organizations consisting of individuals, institutions, and resources. The main aim of grid computing is to give organizations and application developers the ability to create distributed computing environments that can utilize computing resources on demand. Grid computing can leverage the computing power of a large numbers of server computers, desktop PCs, clusters, and other kinds of hardware. Therefore, it can help increase efficiencies and reduce the cost of computing networks by decreasing data processing time and optimizing resources and distributing workloads. Grid allows users to achieve much faster results on large operations and at lower costs. Recent development and applications show that the grid technology represents a critical infrastructure for high-performance DDM and knowledge discovery. This technology is particularly suitable for applications that typically deal with very a large amount of distributed data such as retail transactions, scientific simulation, or telecommunication data that cannot be analyzed on traditional machines in acceptable times. As the grid is becoming a well-accepted computing infrastructure in science and industry, it provides more general data-mining services, algorithms, and applications. This framework helps analysts, scientists, organizations, and professionals to leverage grid capacity in supporting high-performance distributed computing for solving their data-mining problem in a distributed way. The creation of the so-called
Knowledge Grids
on top of data and computational grids is the condition for meeting the challenges posed by the increasing demand for power and abstractions coming from complex data-mining scenarios in business, science, and engineering.
It is not only that DDM infrastructure is changing by offering new approaches through Web services together with the grid technology. Basic data-mining algorithms also need changes in a distributed environment. Most off-the-shelf data-mining systems are designed to work as a monolithic centralized application. They normally download the relevant data to a centralized location and then perform the data-mining operations. This centralized approach does not work well in many of the emerging distributed, ubiquitous, possibly privacy-sensitive data-mining applications. A primary goal of DDM algorithms is to achieve the same or similar data-mining result as a centralized solution without moving data from their original locations. The distributed approach assumes that local computation is done on each of the sites, and either a central site communicates with each distributed site to compute the global model, or a peer-to-peer architecture is used. In the latter case, individual nodes perform most of the tasks by communicating with neighboring nodes by message passing over an asynchronous network. Illustrative examples are networks of independent and intelligent sensors that are connected to each other in an ad hoc fashion. Some features of a distributed mining scenario are as follows:
- The system consists of multiple independent sites of data and computation.
- Sites exchange their results by communicating with other sites, often through message passing.
- Communication between the sites is expensive and often represents a bottleneck.
- Sites have resource constraints, for example, battery power in distributed sensors systems.
- Sites have privacy and/or security concerns.
- The system should have the ability to efficiently scale up because distributed systems today may consist of millions of nodes.
- The system should have the ability to function correctly in the presence of local site failures, and also missing or incorrect data.
Obviously, the emphasis in DDM algorithms is on local computation and communication. Local algorithms for DDM can be broadly classified under two categories:
- Exact Local Algorithms.
These algorithms guarantee to always terminate with precisely the same result that would have to be found by a centralized algorithm. Exact local algorithms are obviously more desirable but are more difficult to develop, and in some cases seemingly not possible. - Approximate Local Algorithms.
These algorithms cannot guarantee accuracy by centralized solutions. They make a balance between quality of solution and system’s responses.
Selection of a type of a local algorithm depends on the data-mining problem and application domain, including the amount of data and their dynamics. In general, approximate approaches are used in cases when the balance between accuracy and efficiency is important, and communications between sites represent a bottleneck. We will illustrate this balance between local computation and communication with a simple approximate algorithm useful in many data-mining applications. For example, if we want to compare the data vectors observed at different sites, the centralized approach will collect these vectors to the central computer and then compare the vectors using whatever metric is appropriate for the domain. DDM technology offers more efficient solutions for the problem using a simple randomized technique.
Vectors
a
= (a
1
, a
2
, … , a
m
) and
b
= (b
1
, b
2
, … , b
m
) are given at two distributed sites A and B, respectively. We want to approximate the Euclidean distance between them using a small number of messages and reduced data transfer between sites A and B. Centralized solution requires that one vector is transferred to the other site, that is,
m
components of one vector are transferred. How does one obtain the same result with less than
m
data transfer? Note that the problem of computing the Euclidean distance between a pair of vectors
a
and
b
can be represented as the problem of computing the inner products as follows:
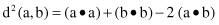
where (
a • b
) represents a inner product between vectors
a
and
b
defined as σ a
i
b
i
, and (
a • a
) is a special case of the inner product representing square of the magnitude of the vector
a
. The reader can easily check the previous relation. If, for example, the vectors a and b are
a
= (1,2,3) and
b
= (2,1,2), then the Euclidean distance may be calculated as d
2
= 14 + 9 − 2×10 = 3. While products (
a • a
) and (
b • b
) can be computed locally, and each result is a single value, the core challenge is to develop an algorithm for distributed inner product computation (
a • b
). A simple, communication-efficient randomized technique for computing this inner product between two vectors observed at two different sites may consist of the following steps:
1.
Vectors
a
and
b
are given on two sites, A and B, respectively. Site A sends to the site B a random number generator seed. (
This is only one passed message
.)
2.
Both sites A and B cooperatively generate a random matrix R with dimensions k × m, where k m. Each entry in matrix R is generated independently and identically from some fixed distribution with mean 0 and a finite variance.
m. Each entry in matrix R is generated independently and identically from some fixed distribution with mean 0 and a finite variance.
3.
Based on matrix R, sites A and B compute their own local matrix products:
∧
a = R a and
∧
b = R b.
Dimensions of new local vectors
∧
a and
∧
b are k, and that means significantly lower than initial lengths of m.
4.
Site A sends the resulting vector
∧
a to the site B. (
This represents k passed messages
.)
5.
Site B computes approximate inner product (
a • b
) = (
∧
a
T
•
∧
b)/k